DB와 App의 인코딩이 다르다면 어떻게 처리해야 할까?
사전지식
캐릭터 인코딩의 종류들:
├── ASCII (영어 + 기본 기호, 128개)
├── ISO-8859-1 (서유럽 언어, 256개)
├── EUC-KR (한국어)
├── Shift_JIS (일본어)
└── Unicode ← 이것도 캐릭터셋 중 하나
├── UTF-8 (인코딩 방식)
├── UTF-16 (인코딩 방식)
└── UTF-32 (인코딩 방식)문자열 집합은 문자들의 집합을 정의하는 표준 규칙이다. 즉 어떤 문자들이 존재하는지를 정의한다.
위의 예시처럼 ASCII, ISO-8859-1(Latin), EUC-KR 등이있다.
Character Set(문자열 집합)은 Character Encoding(문자열 인코딩)과 다르다.
집합은 어떤 문자를 포함 할 지를 정하고, 인코딩을 해당 문자를 어떤 바이트로 변환할지에 대한 구체적 방법이다.
엄밀히 말하면 한글을 표현하는 KS X 1001 (완성형 한글)은 Character Set이며, 이를 매핑에 사용하는 EUC-KR은 Character Encoding이다.
하지만 통상적으로 Character Encoding에 바이트로 표현할 Character Set 맵핑이 있기 때문에 EUC-KR Character Set이라고 칭하는것이다.
좀 더 상세하게 기술하자면, 특정 문자는 Code Page이고, 그 문자에 해당하는 숫자는 Code Point이다.
KS X 1001에서 매핑하는 가 (0x3021)라는 문자를 KS X
1001 문자셋으로 분해하여 EUC-KR로 인코딩하면, 아래와 같은 순서로 진행된다.
'가' 0x3021을 분해하면
상위 바이트: 0x30 (48)
하위 바이트: 0x21 (33)
구역-점 체계를 인코딩한 코드포인트:
0x30 = 구역 16 + 0x20 (16 + 32 = 48)
0x21 = 점 1 + 0x20 (1 + 32 = 33)위 과정을 통해 KS X 1001 코드 포인트를 EUC-KR 바이트로 직접 변환이 가능하다.
과거에는 언어별로 필요한 문자 때문에, 서로 다른 인코딩을 사용하였다. 그 결과 각 사이트간 문자가 깨지는 문제가 발생하였다. 이를 해결하기 위해 유니코드로 말그대로 통합하는 부호를 만들었다.
모든 웹 사이트는 UTF-8 유니코드를 사용하여 각기 다른 언어를 하나에 페이지에서 한번에 보여줄 수 있다. 유니코드는 전세계 언어를 한개로 통합한 인코딩이다.
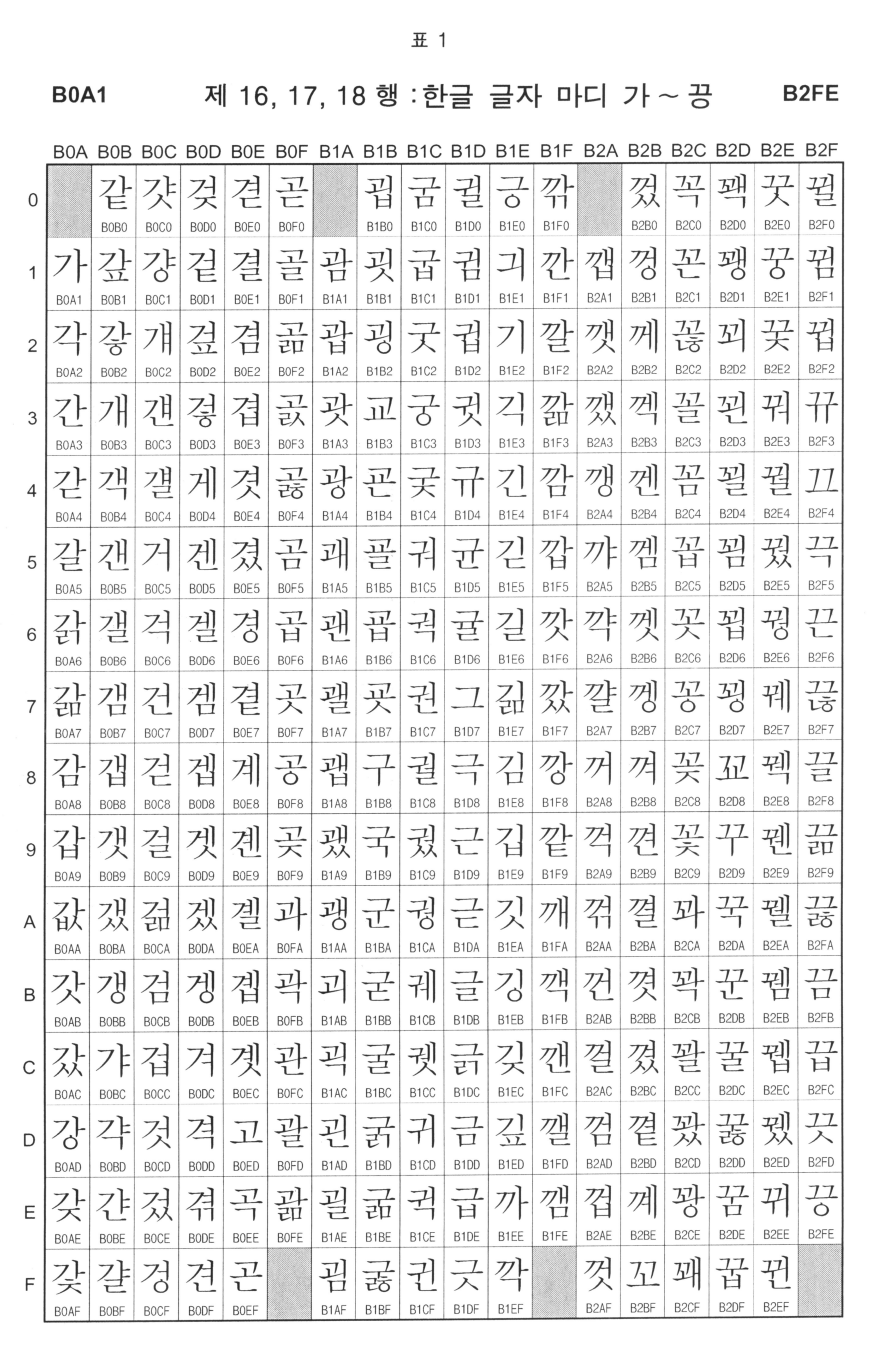
구역·점 방식의 코드 매트릭스
동아시아 권에서 사용하는 여러 한차체계를 표현하기위해 고안된 구역·점 방식은 여러 언어를 포함한 문자열 집합에서 주로 사용된다.
KS X 1001의 경우 94 x 94 매트릭스를 사용하며, 세로축(구역)와 가로축(점)으로 구분 할 수 있다.
각 구역의 0번 점(A0)은 스페이스(깨지지 않는 공백)를 의미하고, 95번(FF)는 끝(EOF)을 알리는 값이다.
따라서 실제 사용되는 값은 94개이다. 그 중 한글은 16 ~ 40구 까지 총 25개의 구역을 사용한다.
| 0 | 1 | 2 | 3 | … | 94 | 95 | |
|---|---|---|---|---|---|---|---|
| 16 | 가 | 각 | 간 | … | 괆 | ||
| 17 | 괌 | 괍 | 괏 | … | 깸 |
16(0xFF) X 6 로 한개의 구역을표현 하고 여기서 실제로 문자가 있는 94개의 점으로 구분된다.
EUC-KR을 UTF-8로 변환하기
가라는 문자의 바이트를 각 인코딩 별로 보면 다음과 같다.
| EUC-KR Code Point | Code Page | UTF-8 Code Point |
|---|---|---|
| 0xB0A0 | 가 | 0xAC00 |
| 0xB3AA | 나 | 0xB098 |
이미 만들어진 EUC-KR 인코딩을 UTF-8로 수학적 변환을 하는 것은 불가능하다. 게다가 유니코드가 만들어질 때 모든 언어를 고려해서 만들어졌기 때문에, 각 문자열 집합 별 매핑 테이블을 제공한다.
EUC-KR Encoding에서 참조하는 KS X 1001의 경우 완성형 문자열 집합 이고, 유니코드(UTF-8, UTF-16)은 조합형 방식을 채택했다.
따라서 EUC-KR 인코딩은 유니코드 컨소시엄에서
제공하는 KS X 1001 매핑 테이블을 사용 해야하며,
그 기준은 가, 나와 같은 코드 페이지로 매핑된다.
Java에서는 jdk.charsets 패키지의 EUC_KR 클래스에서 변환하며, 룩업 테이블 방식으로 UTF-8 Code Point의 인덱스를 찾도록 구성되었다.
즉 EUC-KR Code Point 값을 특정 인덱스로 변환하여 UTF-8 Code Point 룩업 테이블에서 가져와 변환한다.
언어 별로 방법은 다르지만, 룩업 테이블을 매핑하는 것은 동일하다.
예를 들어, EUC-KR 인코딩은 KS X 1001 문자열 집합을 사용하기에 구 16, 점 1이라는 값을 얻을 수 있다.
이 값은 이용해 기존 0xB0A1의 각각의 자리수를 0xA1이라는 값을 빼도 구할 수 있다.
0xB0 - 0xA1 = 15(16-1)
0xA1 - 0xA1 = 0 (1-1)
(구의 인덱스 * 94) + (점의 인덱스)= (15 * 94) + 0 = 1410-1로 인덱스를 만들고, 상위 바이트에 * 94를 하면 구역의 인덱스를 알 수 있다.
EUC-KR 디코더에서는 룩업 테이블에 1410번 인덱스로 U+AC00(가) 값을 갖고 있고 이를 이용해 변환이 가능한 방식이다.
서로 다른 인코딩의 사용
처음부터 캐릭터 인코딩을 유니코드로 사용하면 문제가 되지 않지만, 이미 만들어진 상황에서는 어떻게 해야할까?
예를들어 오래된 .NET Framework를 사용하는 애플리케이션의 경우에는 어떨까. 한국에서는 .NET Framework 초기 버전에서 기본 인코딩이 CP949였다.
파일 저장, 데이터베이스 저장 시 명시적으로 UTF-8이나 Unicode를 지정하지 않으면 CP949로 저장해야했기 때문에, 많은 윈도우 앱의 기본 인코딩이 유니코드를 사용하지 않았다.
이 경우 현재까지 서비스하고 있다면 새로만 들어지는 여러 데이터 관리 툴, 검색툴은 모두 데이터 인코딩을 맞춰야 할까? 그렇지 않다. 가장 간단한 방법은 데이터는 유니코드로, 데이터를 필요로 하는곳에서 해당 인코딩에 맞게 사용하면 된다.
╭─ EUC-KR ─╮ ╭─ UTF-8 ─╮
│ │ -→ │ │
│ Database │ (Convert) │ App │
│ │ ←- │ │
╰──────────╯ ╰─────────╯예를 들어, 검색 기능을 구현한다고 가정하자. 애플리케이션에서 검색어(UTF-8)를 그대로 보내면 Database(EUC-KR)는 알지 못한다. 서로 다른 인코딩을 사용하기 때문이다. 따라서 잘못된 문자열로 쿼리 파라미터가 전달되고, 잘못 찾은 결과(EUC-KR)를 App(UTF-8)로 깨져서 전달 한다.
이를 중간에서 잘 변환해주기 위해서는 설정과 옵션을 올바르게 사용해야한다.
MySQL에서 클라이언트와 서로 다른 인코딩으로 통신하기
MySQL 클라이언트로 결과의 인코딩을 다르게 받아야하는경우, 가장 기본적인 방법은 옵션을 적용하는 것이다.
-- 클라이언트가 DB로 SQL 문을 보낼 때 사용하는 인코딩
SET character_set_client = utf8mb4;
-- 서버에서 클라이언트로 반환하는 결과의 인코딩
SET character_set_results = utf8mb4;
-- 서버 내부에서 쿼리를 처리시 사용하는 인코딩
SET character_set_connection = utf8mb4;따라서 매번 애플리케이션에서 처리해줘야 하기에 일반적으로 애플리케이션은 커넥션 옵션에 클라이언트의 인코딩을 명시한다.
String url = "jdbc:mysql://localhost:3306/mydb?characterEncoding=utf8mb4";characterEncoding 옵션은 위에서 설명한 처리를 간단하게 처리해주기 때문에, 클라이언트에서는 MySQL의 인코딩을 알지 못해도 올바른 처리가 이루어진다.
character_set_database 옵션은 현재 사용중인 DB의 기본 문자열 집합을, character_set_server는 MySQL 서버의 문자열 집합(새로 생성되는 DB에 해당 인코딩을 적용)을
영구적으로 적용하기 때문에 주의 해야한다.