B-tree (Balanced Tree)
B-tree란?
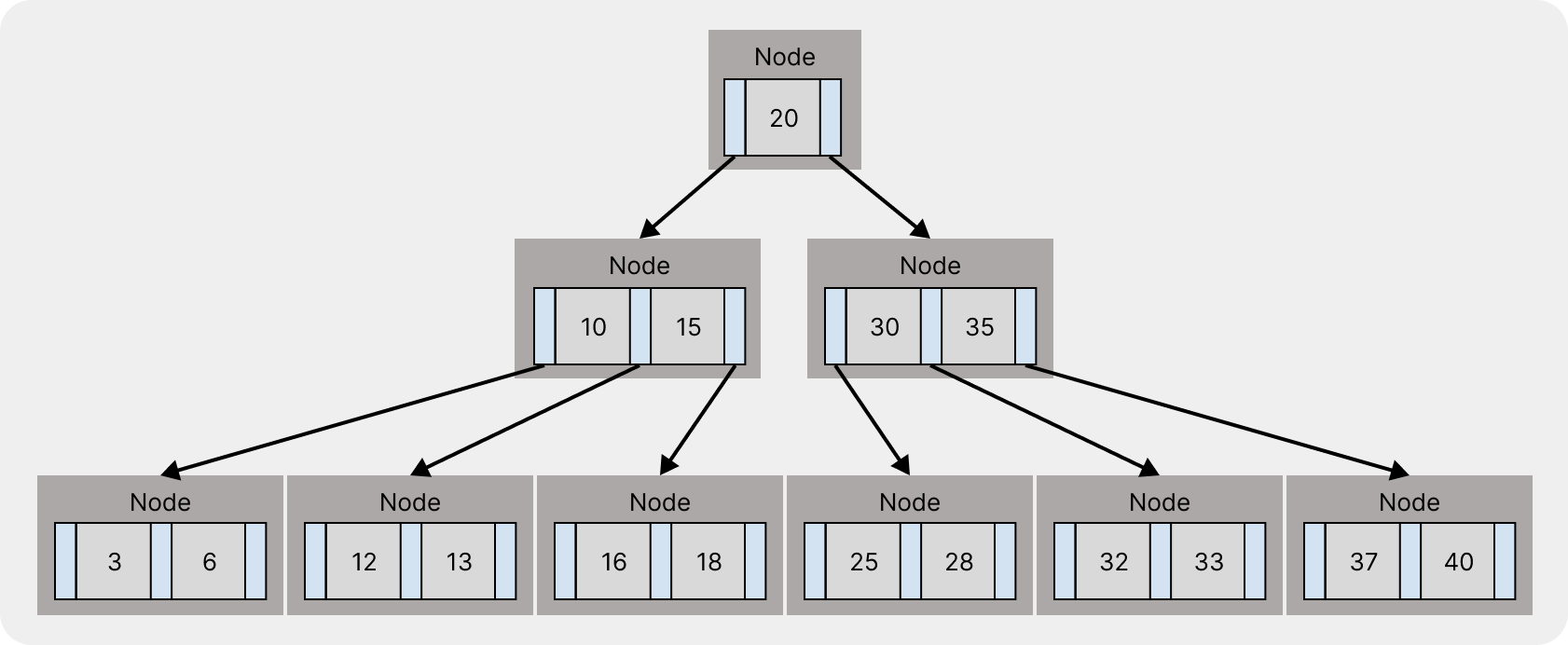
B-tree는 Balanced Tree의 약자로 정렬된 데이터를 관리하고 Log 시간에서 검색, 순차접근, 삽입, 삭제가 가능한 자가균형 트리 자료구조이다.
대용량 데이터를 다룰 때 사용되며 데이터 베이스, 파일 시스템 등 다양한 분야에서 사용된다.
B-tree는 차수(Degree)를 가지며 이 값에 따라 구성 정보가 다음과 같이 달라진다:
degree: 4인 경우
- 최대 자식 수: 4
- 최소 자식 수: (4 + 1) / 2 = 2
- 최대 키 개수: 4 - 1 = 3
정의
Knuth 정리에 따라, m 차 B-tree는 다음의 속성을 만족하는 트리이다.
- 각 노드는 최대 m 개의 자식을 갖는다.
- 루트와 리프 노드를 제외한 각 노드는 최소 ⌈m/2⌉ 개의 자식을 갖는다.
- 루트노드는 리프노드가 아닌한 최소 두개의 자식노드를 갖는다.
- 모든 리프노드는 동일한 레벨에 존재한다.
- k 개의 자식노드를 가지는 노드는 k-1 개의 키를 가진다.
각 내부 노드의 키는 서브트리를 구분하는 분리값으로 작용한다. 예를들어 내부 노드가 3개의 자식노드를 갖고 있다면, 2개의 키를 가지고 있어야만 한다: a1 와 a2.
좌측 서브트리의 모든 값은 a1 보다 작고, 중앙 서브트리의 모든 값은 a1 와 a2 사이에 있으며, 우측 서브트리의 모든 값은 a2 보다 크다.
내부 노드
내부 노드는 루트노드와 리프노드를 제외한 모든 노드이다. 이는 일반적으로 자식 포인터와 키의 집합으로 정렬 돠어 표현된다. 각 내부 노드는 최대 U 개, 최소 L 개의 자식노드를 포함한다. 따라서, 키의 개수는 항상 자식노드(L-1 에서 U-1 사이의 키 개수) 개수 -1 이다. U 는 2L 또는 2L - 1중에 하나여야 한다. 그러므로 각 내부 노드는 최소한 절반 이상 채워진다. U 와 L 사이의 관계는 다음을 나타낸다.
- 합법노드를 만들기 위해 결합될 수 있는 반만 채워진 두개의 노드
- 두개의 합법노드로 분리될 수있는 한개의 꽉찬 노드 (만약 한개의 키를 부모 노드로 삽입할수 있는 공간이 있다면)
이러한 속성은 B-tree에 새로운 값을 추가하거나 삭제가 가능하게 만들고 B-tree 속성을 지키기 위해 트리를 조정한다.
루트 노드
- 루트노드의 자식 개수는 내부노드와 동일한 상한은 있지만, 하한은 없다. 예를들어 전체 트리에 키의 개수가 L-1 보다 적을 때, 루트노드는 자식노드가 없는 단일 노드인 상황이다.
리프 노드
- Knuth 용어로 "리프" 노드는 실제 데이터 객체 / 청크이다. 다른 저자들이 말하는 "리프"는 리프 노드 바로 위에있는 내부 노드에 해당:
- 이 노드 들은 키(최대 m-1, 루트가 아니면 최소 m/2 -1개)와 데이터 객체/청크를 가리키는 포인터만 저장
노드 (Node)
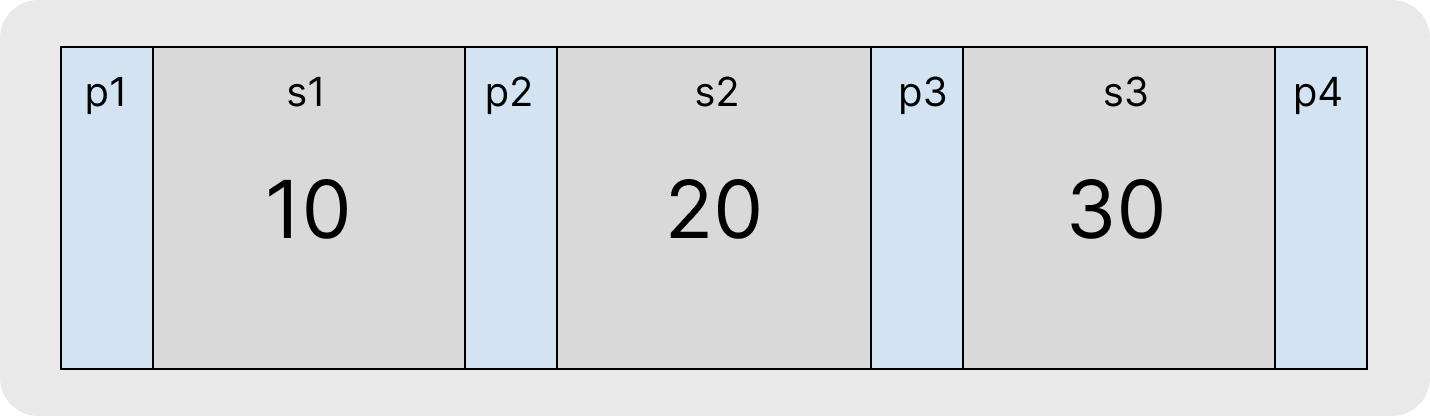
노드는 자식 노드들의 포인터들과 키들로 구성된다. 이미지에서 보이는 p1, p2...pn은 자식노드 들의 포인터를 의미한다. s1, s2, s3는 키를 의미한다. 데이터를 검색할 때, 키들중에서 비교를 하고 사잇 값이라면 해당 범위의 자식노드로 이동한다.
노드의 구조
다른 트리들과 마찬가지로 B-tree도 세가지 타입의 노드들로 표현될 수 있다: 루트, 내부, 리프.
노드의 구성요소는 다음과 같다:
- K: B-tree의 각 노드에대한 검색 키의 최대 개수. (이 값은 전체 트리에서 동일하다)
- pti: 하위트리를 시작하는 자식노드에 대한 포인터.
- pri: 데이터를 저장하는 레코드에 대한 포인터.
- ki: 0부터 시작하는 노드인덱스 i의 검색키.
B-tree에서는 노드에대해 다음의 속성들이 관리된다.
- B-tree내 ki(키)가 존재한다면 *ki-1*는 존재. (오름 차순 정렬에 대한 균형 관리를 의미)
- 모든 리프노드는 동일한 조상 노드의 개수를 가진다.(트리의 높이를 일정하게 유지하는 관리를 의미)
B-tree에서 내부 노드는 다음의 형식을 갖는다:
| pt0 | k0 | pt1 | pr0 | k1 | pt2 | pr1 | ... | kK-1 | ptK | prK-1 |
|---|
| k0 존재 시 pt0 | ki-1 , ki 존재 시 pti | ki-1 존재, ki 미존재 시 pti | ki , ki-1 미존재 시 pti | ki 존재 시 pri | ki 미존재 시 pri |
|---|---|---|---|---|---|
| k0 보다 작은 키들을 가진 서브트리를 가리킨다. | ki-1 보다 크고 ki 보다 작은 키들을 가진 서브트리를 가리킨다. | ki-1 보다 큰 키들을 가진 서브트리를 가리킨다. | 여기서 pti 는 비어있다. | ki 와 같은 값인 레코드를 가리킨다. | 여기서 pti 는 비어있다. |
데이터 검색
검색은 루트 노드부터, 리프노드까지 순차적으로 이어지며 logmN의 시간 복잡도를 가진다.
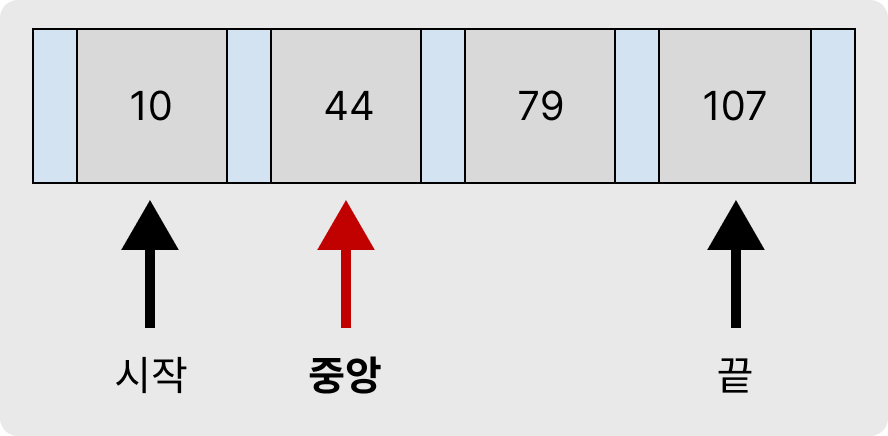
노드 내에서 비교는 항상 중앙(중간 값)하고만 이루어지는데, 검색 과정에 따라 중앙이 바뀐다.
(시작: 0, 중앙: 1, 끝: 3)
위 이미지처럼 시작: 0, 끝: 3이라면 중앙은 (0 + 3) / 2 = 1이 된다. 이 공식으로 범위가 정해질 때 마다 중앙이 바뀐다.
중앙 값이 정해지면, 비교를 시작하고 중앙 < 찾는 값이라면, 시작 포인터는 중앙 +1: 2가 된다.
찾는 값 < 중앙이라면, 끝 포인터는 중앙 -1: 1이 된다.
그럼 다시 (2 + 3) / 2 = 2가 중앙이 되고 다시 비교한다.
(시작: 2, 중앙: 2, 끝: 3)
이때 찾는 값 < 중앙(2)이라면 시작(2)보다 작은 값이기 때문에 44와 79사이의 포인터로 다음 자식노드로 이동하고,
중앙(2) < 찾는 값 이라면 또다시 시작 포인터를 중앙 +1: 3으로 이동한다.
이 과정에서 만약 중앙 값과 비교할 때 같다면, 해당 값 탐색에 성공한것이다.
이런 식으로 루트노드부터 검색이 이루어 지면 아래와 같이 처리된다.
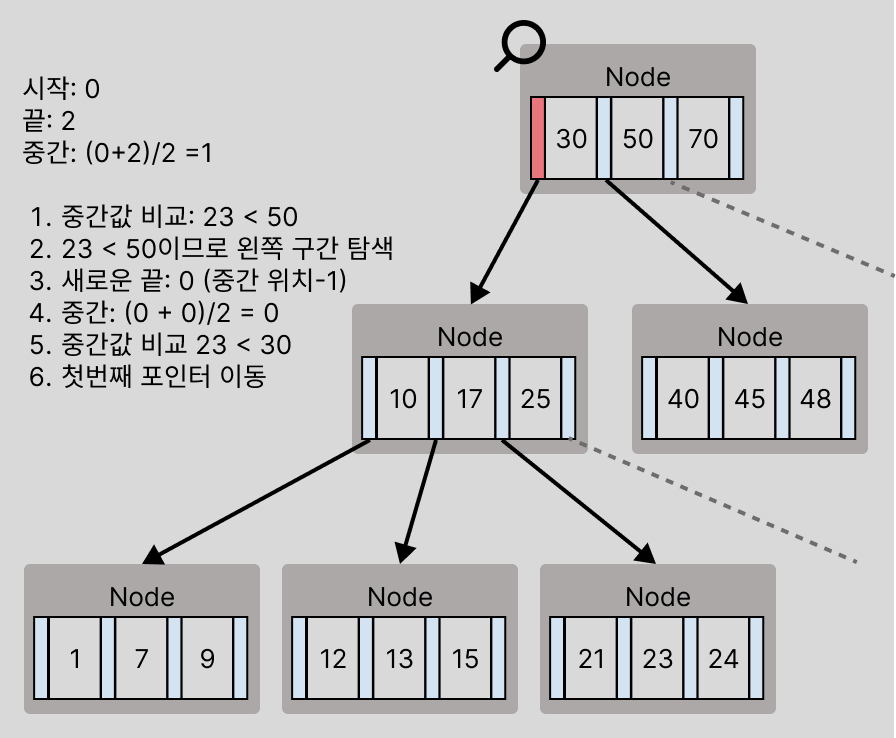
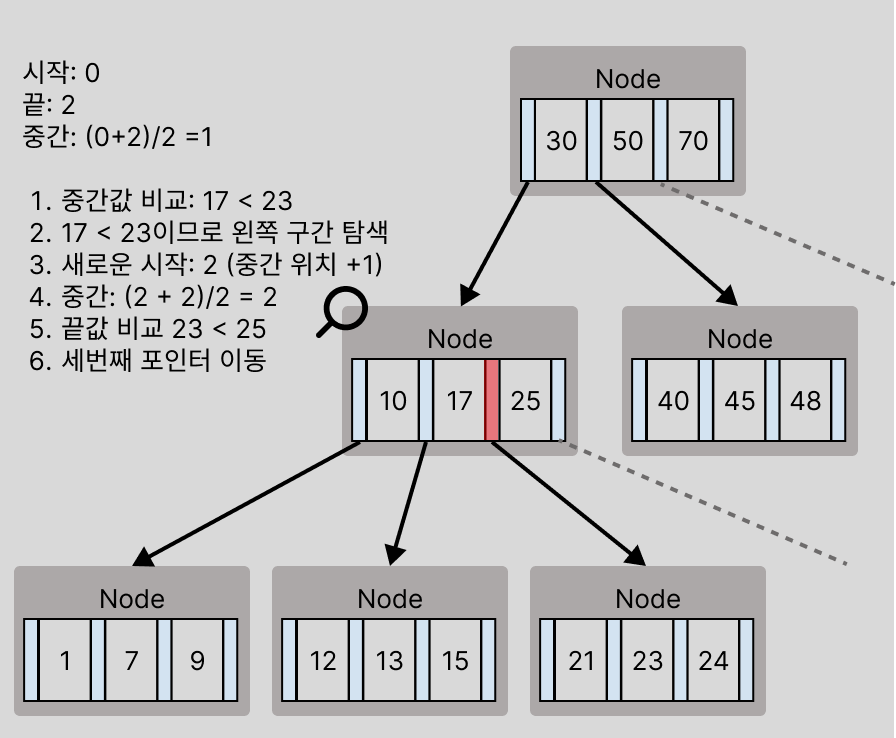
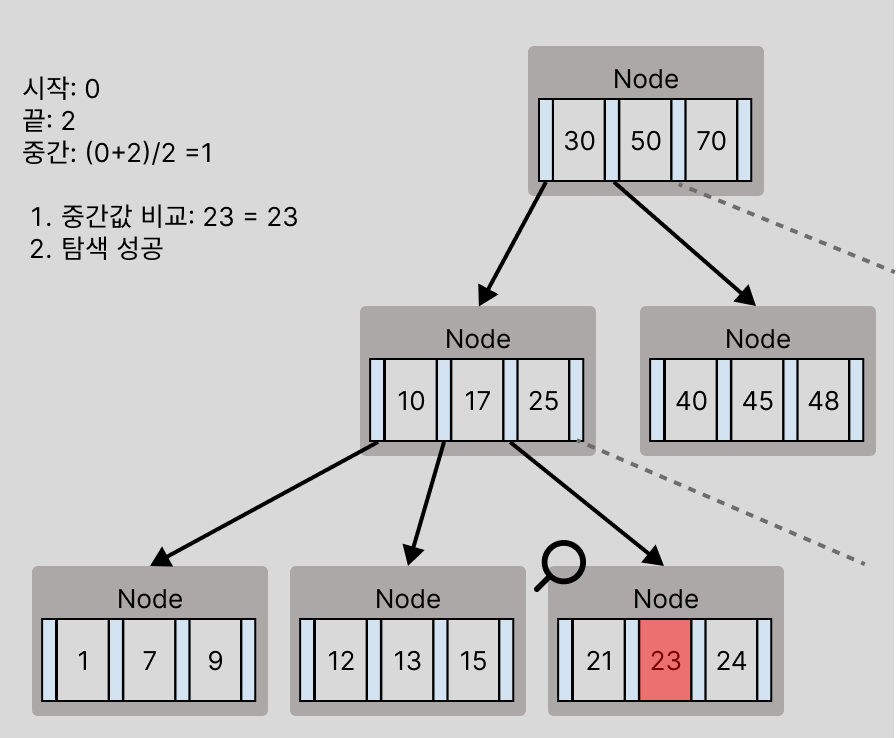
데이터 삽입
검색할 때와 마찬가지로 루트노드 붙어 리프노드까지 이동하며 삽입할 위치를 찾는다.
실제 삽입은 리프노드에서 제일 먼저 일어나며, 그 과정들을 다음에 설명한다:
일반 적인 데이터 추가
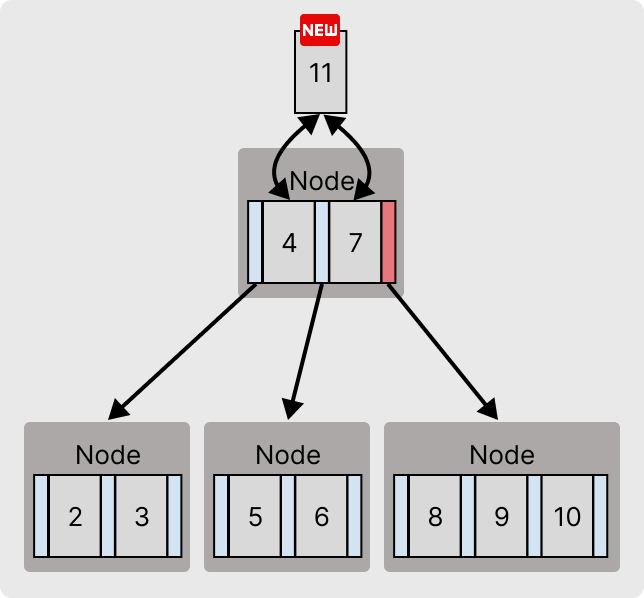
위의 구조에서 값 11이 추가되면 루트 노드에서는 삽입 위치를 찾기위해 검색에서 사용한 방법대로 이분탐색으로 이동할 포인터를 찾는다.
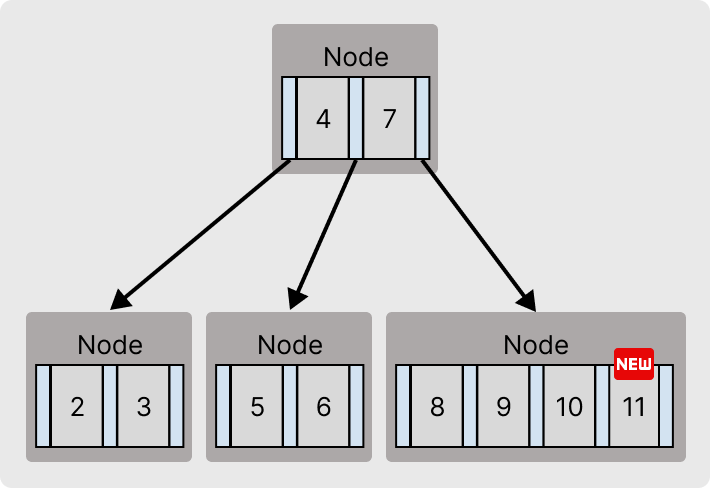
자식노드의 포인터로 이동된 뒤, 기존의 키들과 비교하여 삽입할 위치를 찾고 최대 키 개수를 넘지 않았다면 그 자리로 삽입된다.
데이터 추가에 대한 노드 확장
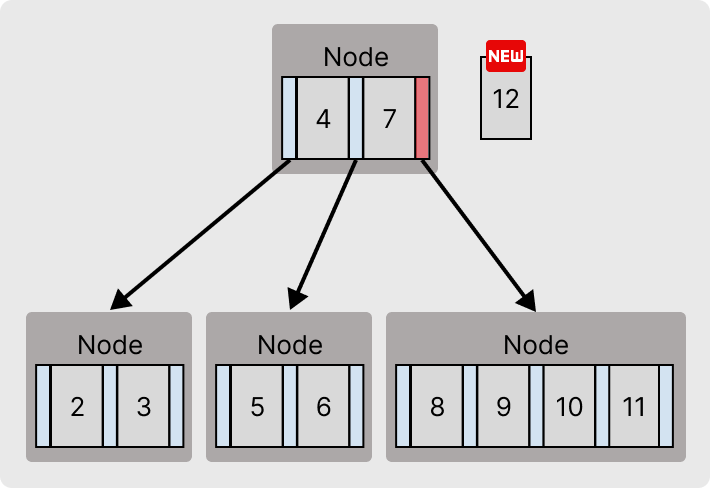
값 12가 추가 되면 이전과 동일하게 이동할 포인터를 찾는다.
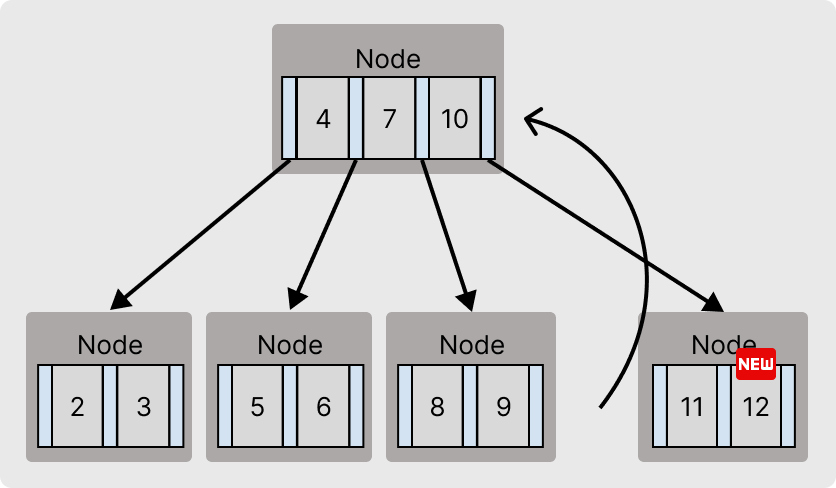
기존 [8, 9, 10, 11]에서 12가 추가되면 [8 ,9, 10, 11, 12]가 되어 최대 키 개수를 위반하게 된다.
이 경우에는 중간 값(10)을 기준으로 노드를 분할하여, 중간값의 왼쪽 포인터를 [8, 9] 노드에 연결, 오른쪽 포인터를 [11, 12] 노드에 연결한다.
그리고 중간 값10은 부모노드로 이동하여, 부모노드에서도 삽입을 시도한다.
만약 부모노드에서도 최대 키 개수를 넘어가면, 부모노드도 분할하여 중간값을 부모노드로 이동하고, 부모노드의 부모노드로 이동하여 삽입을 시도한다.
데이터 삭제
앞서 설명한 m차 B-tree의 노드 규칙은 다음과 같다.
- 최대 자식 수:
m - 최소 자식 수:
m / 2 - 최대 키 개수:
m - 1
제약에 걸리지 않는 다면 삭제후 별다른 조치가 없다. 데이터 삭제에 대해 처리 할수 있는 조치는 병합과 재분배가 있다.
데이터 삭제에 대한 재분배
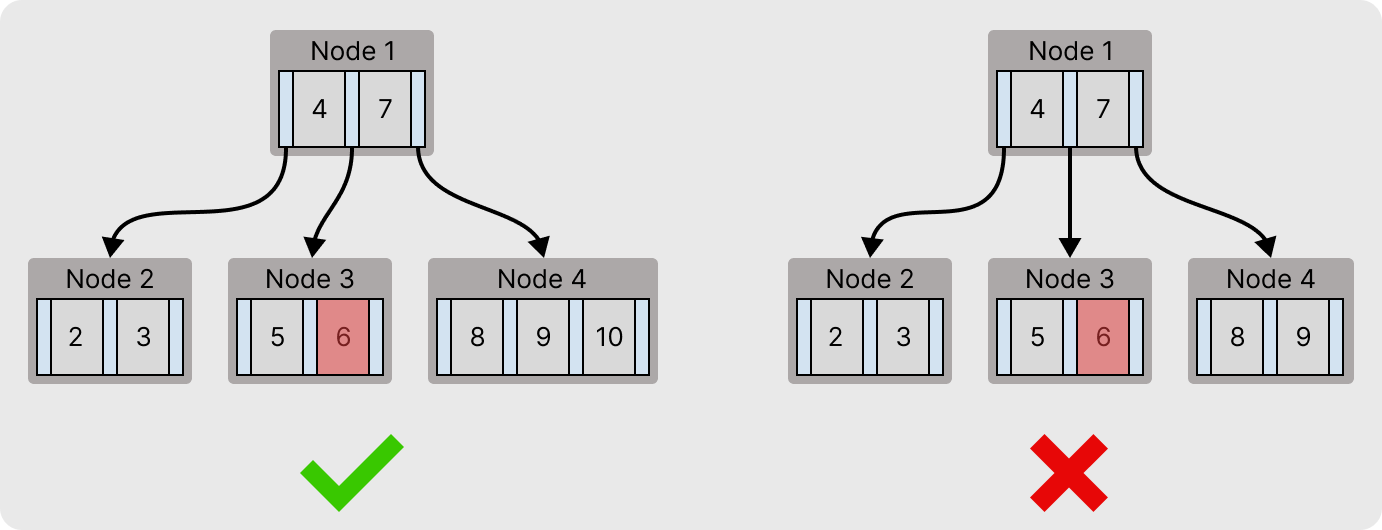
키가 삭제되고 최소 키 개수 규칙에 위배 되었다면, 형제 노드에 여유가 있을 때 재분배가 가능하다.
예를 첫번째 b-tree는 Node 3의 6번 키가 삭제 되더라도, Node 4에 키가 여유(2 < 3) 있기 때문에 재분배가 가능하다.
반대로 두번째 b-tree는 Node 3의 6번 키가 삭제 되더라도, Node 2와 Node 4에 키가 여유(2 < 2)없기 때문에 재분배가 불가능하다.
만약 재분배가 가능한 조건이라면 다음과같이 처리된다.
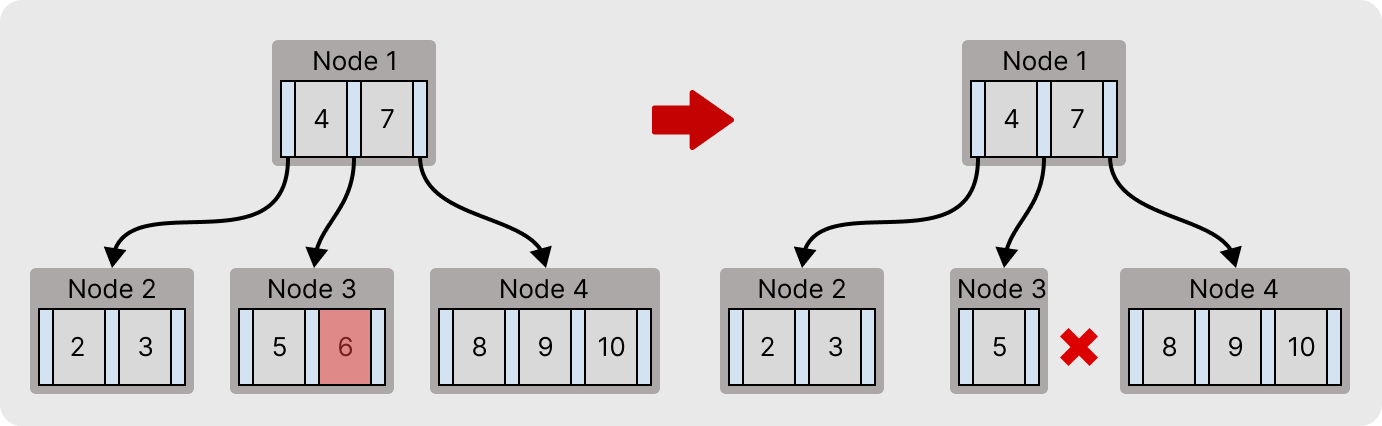
위 트리에서 6을 삭제한다고 할 때, 삭제가 이루어지고 나서 Node 3는 최소 키 개수 규칙을 위배한다.
이 경우 Node 4에서 키를 하나 가져와 Node 3에 삽입하면 최소 키 개수 규칙을 지킬 수 있다.
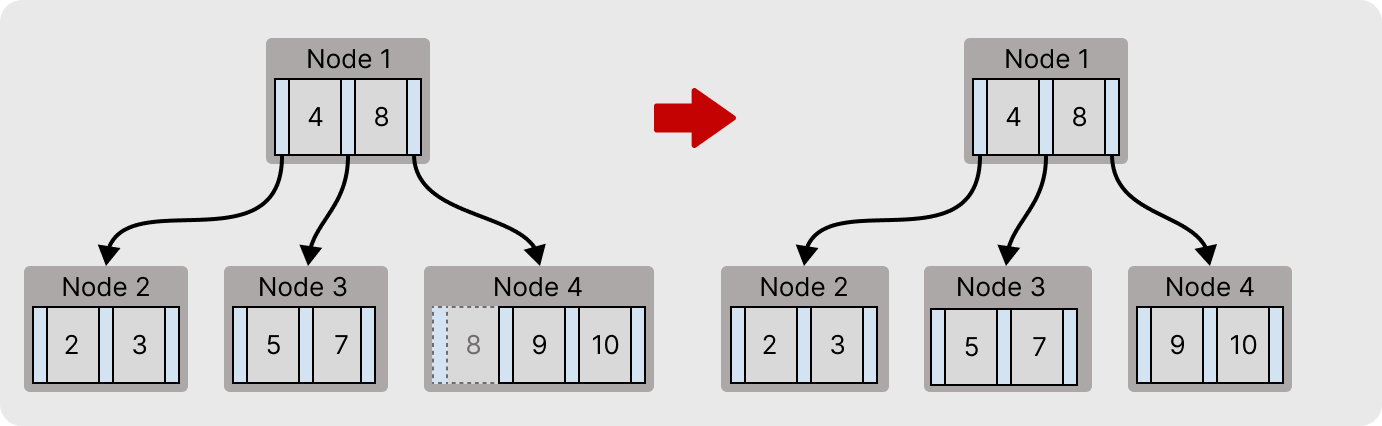
재분배가 가능하다면 여유로운 노드(Node 4)를 가리키고 있는 포인터에 붙은 키를 자식노드로 내린다. 그리고 부모노드에서는 재분배된 키를 선별하기위해 가장 작은키 (왼쪽에서 가져온다면 가장 큰 키)를 부모노드로 이동시킨다.
이렇게 되면 재분배가 되어 최소 키 개수 규칙을 지킬 수 있게 된다.
데이터 삭제에 대한 병합
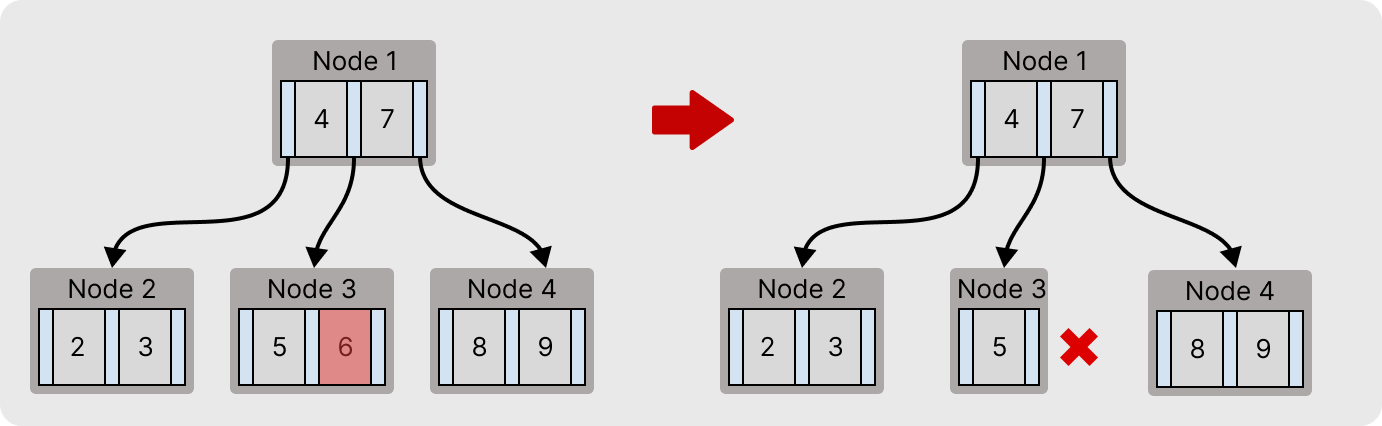
위와 같은 4차 B-tree가 있을 때 Node 3의 6번 키를 삭제하면, Node 3는 Underflow가 발생한다.
이때 Node 2와 Node 4는 모두 최소 키 개수만큼만 가지고 있기 때문에 재분배가 불가능하다.
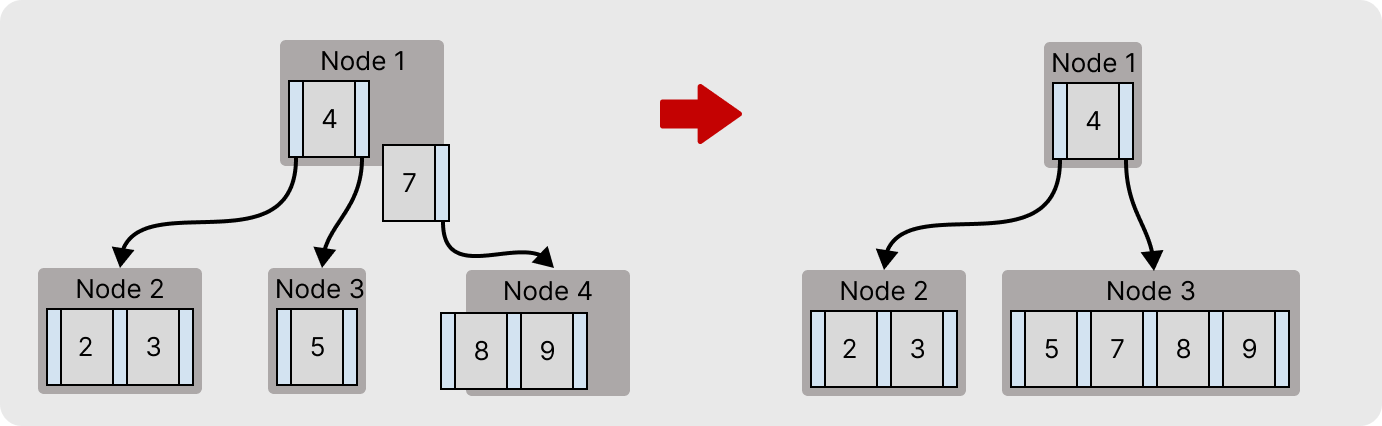
이런 경우에는 형제 노드를 골라 해당 형제노드와 연결되어 있는 부모키를 가져와 병합한다.